
■学習数理情報学
数理第6研究室は学習数理情報学を専門とする研究室です。
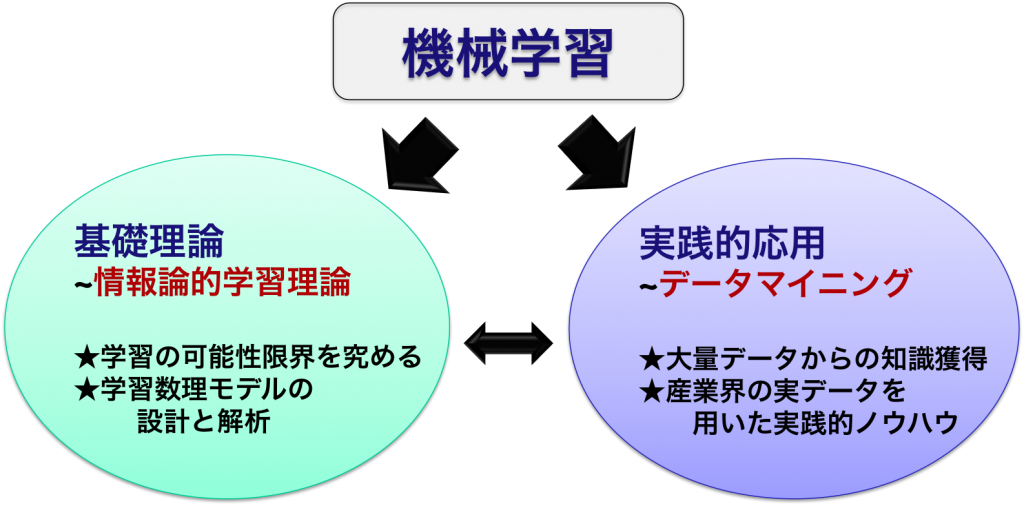
学習数理情報学とは、大量データから計算機がいかに有用な知識を獲得できるか?といった問に対して、数学モデルを中心にアプローチする学問です。これは機械学習とも呼ばれています。
本研究室の学習数理情報学は機械学習の理論的側面である情報論的学習理論と実践的側面であるデータマイニングの両輪から成ります。
-
■情報論的学習理論
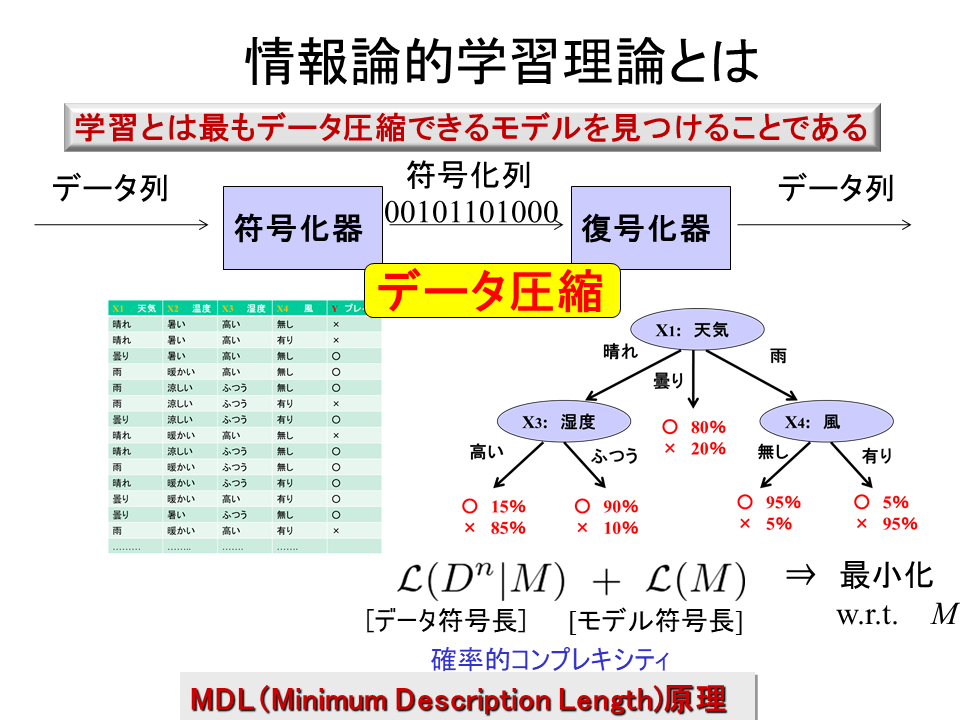
- 「機械はどこまで学習できるか?」この問いに対して情報理論・統計学からアプローチしています。特に、MDL原理(Minimum Description Length Principle; 記述長最小原理)と呼ばれる情報理論の基本原理を軸にして、
- ・モデル選択 (特に、潜在変数モデルを対象とする)
- ・動的モデル選択
- ・変化検知、潜在構造変化検知、異常検知
- ・変化予兆検知
- ・オンライン学習
- ・分散協調学習
- など幅広い学習問題に有効な機械学習アルゴリズムを統一的に導き出しています。
- 情報論的学習理論において一貫する考え方は、
- 「学習とはデータを最短に圧縮する戦略を見つけることである」
- という考え方です。
- MDL原理の立場から統一的に学習理論をまとめた本としては拙著 「情報論的学習理論」をご覧ください
-
■データマイニング・データサイエンス
- ・データマイニング基礎
- 大量データからの知識発見技術(異常検知、変化検知、ネットワークマイニング、など)を研究しています。特に、データの奥底に眠る潜在的知識の最適な形を抽出し、その変化を解析する研究を行っています。
- そこで、以下の2つの新しい学問コンセプトとして
- 「潜在的ダイナミクス(Latent Dynamics )」
- 「潜在的構造最適化 (Latent Structure Optimization)」
- を提唱しています。
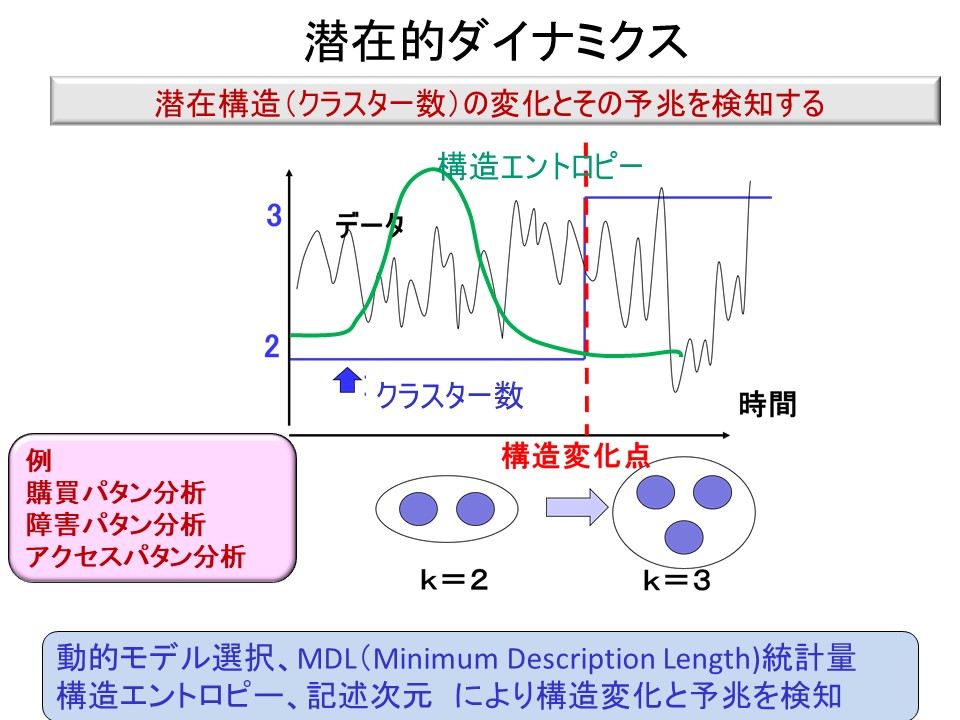
- 潜在的ダイナミクスは、潜在空間の変化に着目し、異常の早期発見や変化の予兆検知を目指すものです。これを実現するために、動的モデル選択、MDL変化統計量、構造エントロピーといった概念を創り出してきました。潜在的ダイナミクスについては、また、電子情報通信学会誌2014年5月号(Vol97, No.5)の特集「データを読み解く技術」の1テーマとして特集されています。
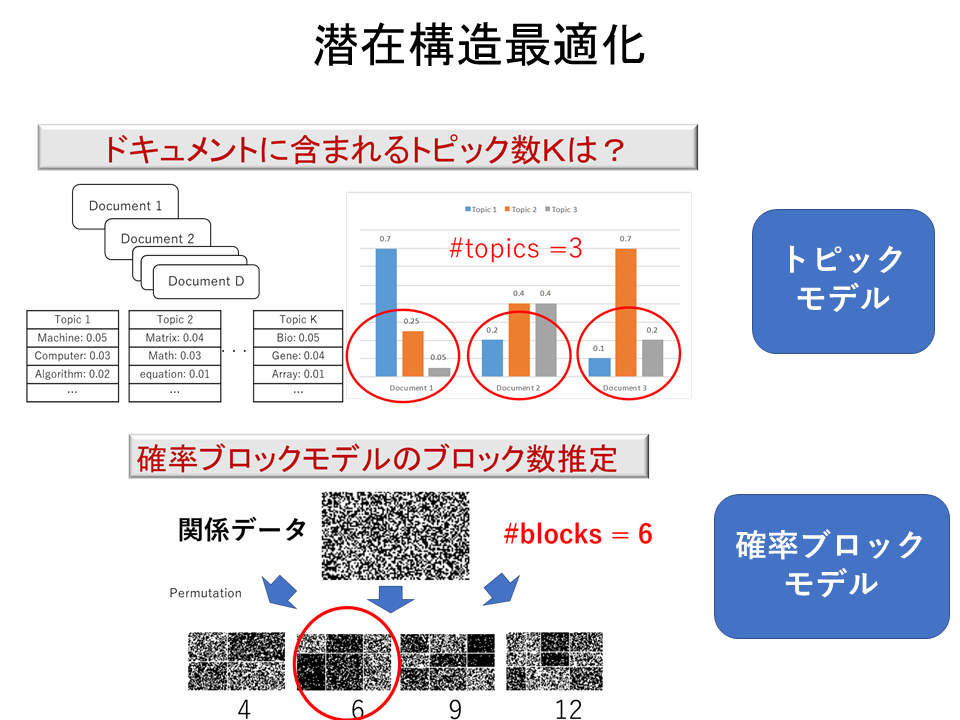
潜在的構造最適化は、データの背後にある潜在的トピックの数や、潜在的関係ブロックの数などの最適数をMDL原理の立場から決定しようとするものです。最近では、これを実現するために、分解型正規化最尤符号規準という基準を提唱しています。
- ・データマイニング応用
- 現実の複雑なデータに上記技術を応用して効果を生み出ための適用技術の研究を行っています。特に、これらの成果を
- ・医療(緑内障進行予測 など)
- ・交通リスクマイニング
- ・マーケティング
- ・ソーシャルネットワーク解析
- ・教育データ解析
- などに活用して効果を生んでいます。その際、各種業界のエキスパート一緒に現実のデータの分析を行い、どうしたら知識は価値をもつのかを研究しています。
- 山西研究室は東京大学データサイエンス養成講座(DSS)をサポートしています。DSSと連携して、企業との共同研究に積極的に取り組んでいます。その中で実データに触れ、解析する機会を多く提供しています。
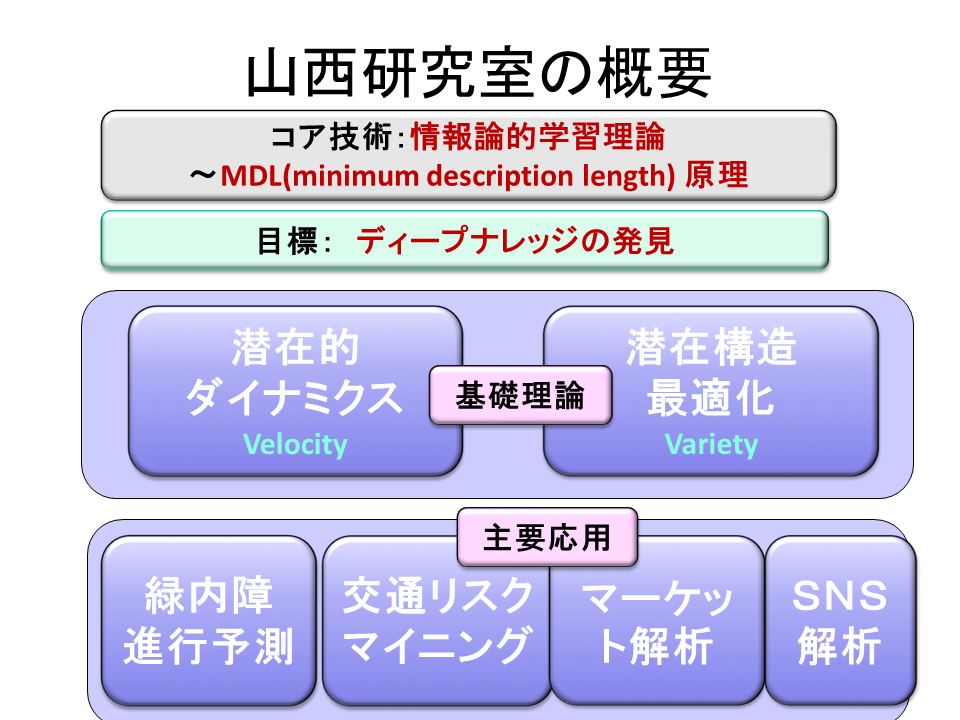
■ディープナレッジの発見と価値化
上記、本研究室の情報論的学習理論とデータマイニングの技術を集結させて、2013年よりJST-CRESTの「ビッグデータ基盤」の中で「複雑データからのディープナレッジの発見と価値化」というテーマの研究に取り組んでいます。ディープナレッジとは、データの表面からは分からない、潜在空間の奥底に潜む深い知識のことです。これを抽出し、価値に変えるための研究を行っています。
昨今のビッグデータブームでは、データの大量性のみが注目されていますが、ビッグデータの扱いを困難にしているのは、その動的特性(velocity)や多様性(variety)や高次元性など、データの複雑性にあると考えられます。そこで、複雑なデータには、その背景に深い構造(ディープナレッジ)があると考え、その姿を読み解くことを目指します。つまり、ディープナレッジを通じてデータの全体像を俯瞰し、将来のデータの動きを的確に予測することを目的として研究を行います。このようなディープナレッジの発見と価値化について、潜在的ダイナミクス、関係データ予測、ネットワーク理論、を含む最先端データ技術を総動員して取り組んでいます。より詳しくは、CRESTについてのページで説明していきます。
ディープナレッジについては、IBM Provision誌(No.78, 2013)のインタビュー記事に詳しく述べております。
詳細はこちら
■眼科学研究について
詳細はこちら





