 Japanese
Japanese
 English
English








▼研究内容の詳細
1.確率的知識の学習理論の研究(1990年-1994年)
統計的学習の3つのモデルの構築
1. 確率的PAC学習モデル Stochastic probably approximately correct Model 確率規則の近似学習モデル
2. 確率的逐次学習モデル Loss Bound Model 確率予測のモデル
3. 確率的識別モデル PAD(Probably Almost Discriminative) Model 識別学習のモデル
それぞれのモデルは、学習の問題を推定・予測・検定といった統計的問題に還元しながら学習に必要なコンプレキシティをも考慮した新しい学習評価のための形式的理論です。またそれらのモデルの中で、有効な推定・予測・検定のための学習アルゴリズムがMDL(Minimum Description Length)principle(記述長最小原理)から統一的に導かれることを示し、その理論的性能を明らかにしました。この結果はMDL原理自体の理論的解明に貢献しています。
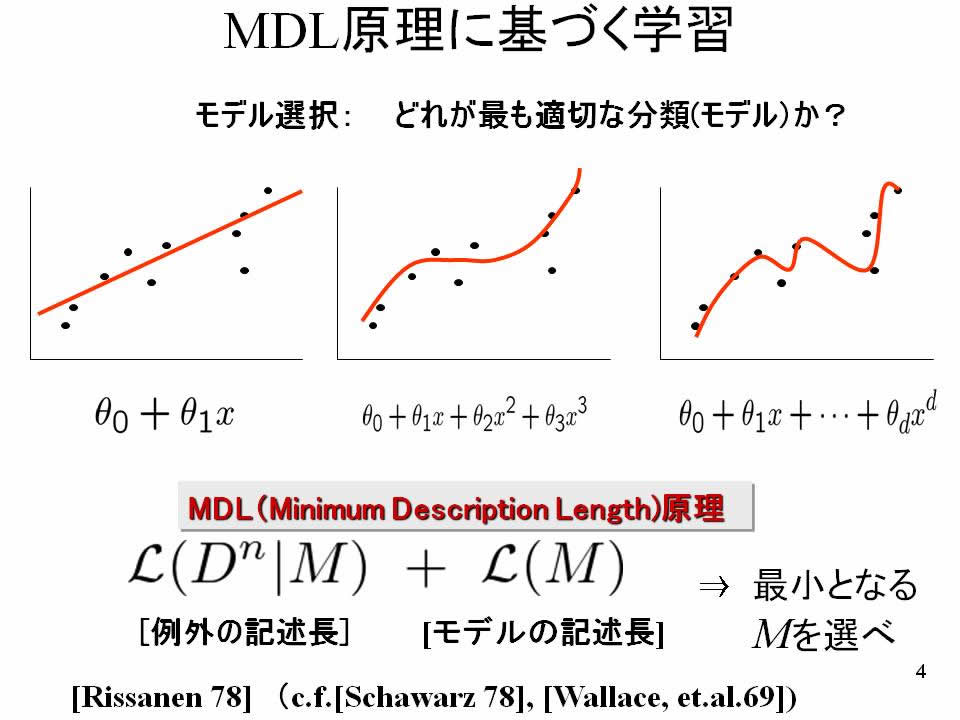
図1: MDL原理に基づく学習
例えば、MDL原理を統計的モデル選択に用いるとしましょう。 与えられたデータに対して、何次の多項式を当てはめればよいかといった問題を考えます。次数の低い単純な曲線を当てはめると、例外を多く生み出します。明らかにデータの内在的構造の本質を捉えきれていません。一方で、次数の高い複雑な曲線を当てはめると、データの不規則性に過剰適合してデータの内在構造の本質から遠ざかります。
そこで、曲線の複雑さの記述長とその曲線に当てはまらない例外データの記述長の総和を最小にするように曲線を選ぶことにより、最適な曲線がデータに応じて決定できるのです。
2.確率的コンプレキシティの拡張と機械学習応用の研究(1995年―2007年)
MDL原理の基礎には「確率的コンプレキシティ」(Stochastic Complexity,略して「SC」)とよばれる情報理論的概念があります。これは一言で言うと、「確率モデルのクラスを用いてデータ圧縮する時の記述長」のことです。

図2: 確率的コンプレキティ
MDL原理によれば、SCを最小化するデータ圧縮アルゴリズムそのものが、最も性能の良い機械学習アルゴリズムであると見なされます。 ここでは、SCを以下のような形で拡張し、機械学習アルゴリズムの設計と解析における有効性を立証してきました。
SC3つの拡張
1. 拡張型確率的コンプレキシティExtended Stochastic Complexity 一般の損失を用いた統計決定理論的拡張
2. 動的モデル選択 Dynamic Model Selection; DMS 非定常情報源への拡張
3. 分散協調ベイズ学習方式 Distributed Cooperative Bayesian Learning 分散情報源への拡張
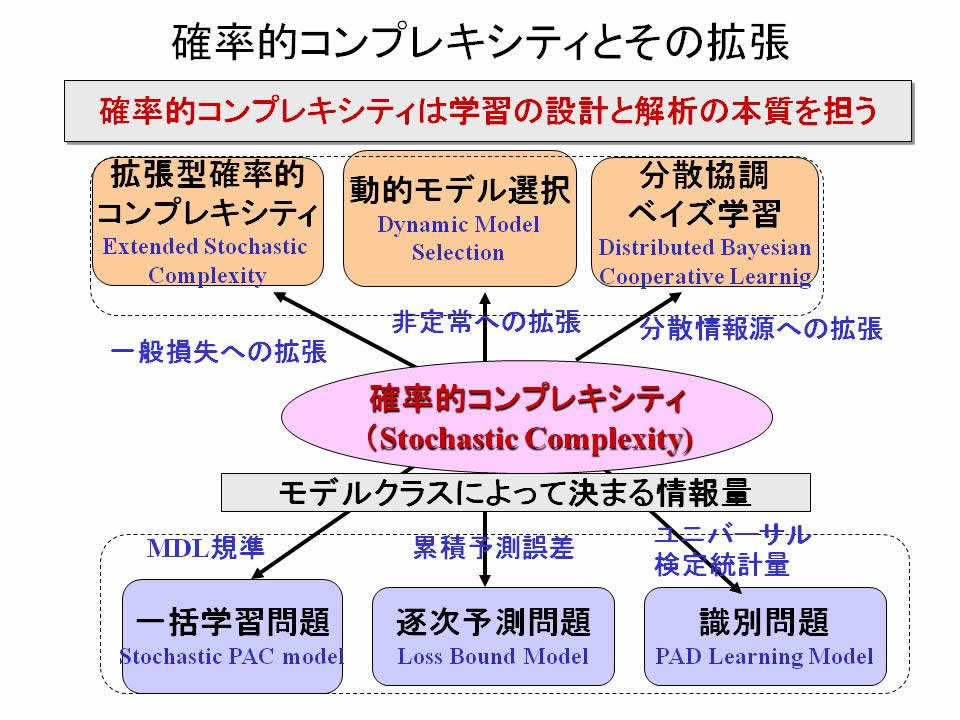
図3: 確率的コンプレキシティとその拡張
こうした研究は情報論的学習理論とよばれる分野に貢献しています。
3.データ・テキストマイニングの研究(1999年―2008)
上記の理論をベースにして、データマイニング、テキストマイニングといった分野で機械学習の応用に取り組んでいます。
データマイニングとは、大量のデータからの知識発見です。現在、特に、データの動的でヘテロ(非一様)な性質に対応したマイニングを行うことが最も重要です。このようなマイニングの技術を、動的ヘテロデータマイニング技術とよんでいます。
その中で、特に以下の分野の体系を構築しました。
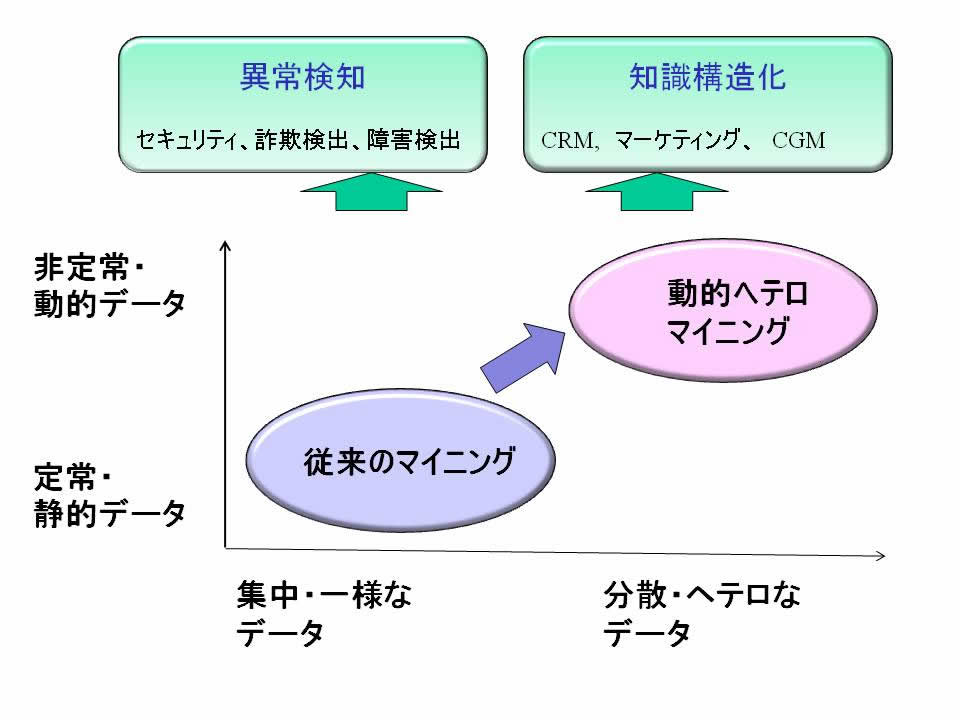
図4: 動的ヘテロマイニング
3-1. データマイニングによる異常検知 (Anomaly Detection with Data Mining)
・技術: 外れ値検出・変化点検出・異常行動検出、集合型異常検知、隠れ変数マイニング
・ビジネス領域: セキュリティ、詐欺検出、不審行動検出、製造業における障害検知、セットワーク障害検出
山西健司著「データマイニングによる異常検知」(共立出版)において、これまでの異常検知に関する研究活動の集大成を見ることができます。
3-2. 知識構造化 (Knowledge Organization)
・技術: テキスト分類・トピック分析・自由記述アンケート分析
・ビジネス領域: CRM(Customer Relationship Management)、ナレッジマネジメント, CGM(Consumer Generated Medias)分析
4. 複雑データからのディープナレッジの発見と価値化の研究(2009年―現在)
データマイニングにおいて、データの表層的な関係性を調べても必ずしも価値ある知識は発見できません。
データの背後にある潜在空間にこそ貴重な情報が含まれていることがあります。
そのための潜在空間を適切にモデリングし、その構造と変化を通じてデータの本質を読み解こうとするのが、
「複雑データからのディープナレッジの発見(Deep Knowledge Discovery from Complex Data)」です。
それには以下の2つの方向性を設定しました。
4-1 潜在構造最適化(Latent Structure Optimization)
4-2 潜在的ダイナミクス(Latent Dynamics )
■潜在構造最適化について:
例えば、文書の構造を考えるとしましょう。文書は単語の集合です。これは目に見えるデータです。しかし、その背後には、単語が何を意図した内容かを示すトピック(topic)が存在します。このトピックは観測できない潜在変数であり、トピックを潜在変数とする確率モデルをトピックモデルと呼びます。潜在構造最適化とはトピックモデルに内在するトピックの最適な数をデータから推定することです。
また、コミュニケーションネットワークを考えましょう。情報の発信者をノードとし、誰と誰がどれだけ強くつながっているかをエッジの重みで表すとします。このようなネットワークの背後には、どういうグループがまとまってつながっているかを示すコミュニティ(community)が存在します。これも外からは観測できない潜在変数です。コミュニティを潜在変数とする確率モデルを確率的ブロックモデルと呼びます。ここで、確率ブロックモデルに内在するコミュニティの最適な数をデータから推定することもまた、潜在構造最適化です。
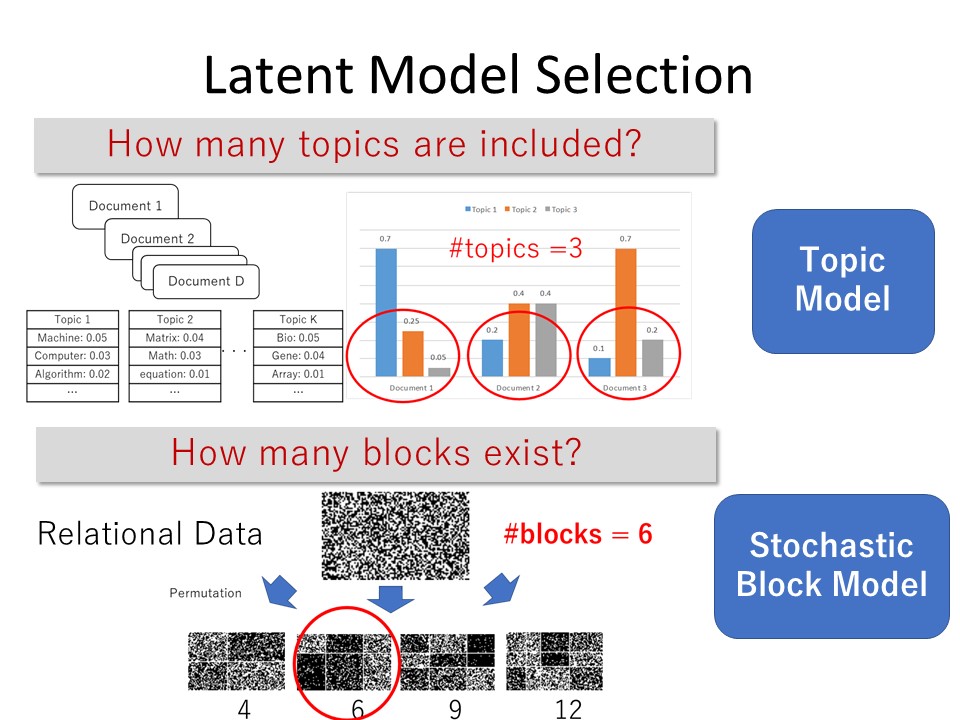
図5: 潜在変数モデル選択
潜在構造最適化のための新しい、潜在変数モデル選択規準として以下の2つの規準を新しく提案しています。
・潜在的確率的コンプレキシティ(Latent Stochastic Complexity)
・分解型正規化最尤符号長(Decomposed Normalized Maximum Likelihood (DNML) Codelength)
これらは、潜在変数を補って得られる完全変数化モデルをMDL原理の立場から選択する規準です。
特に、DNMLでは、潜在変数Zと観測変数Xを階層的に正規化最尤符号化して、総和を最小にするモデルを選択します。 この規準によって、トピックモデルのトピック数や、確率ブロックモデルのブロック数や、ガウス混合モデルの混合数などを最適化できます。 この規準が理論的な最適性と実際上優れた性能をもつことを明らかにしてきました。
潜在構造最適化の成果はKDD2019におけるMDL tutorial資料に見ることができます。

図6: 分解型正規化最尤符号長規準(DNML)
■潜在的ダイナミクスについて:
各時刻にまとまった多次元データが与えられ、これをクラスタリングすることを考えます。 たとえば、1つのデータが1つのユーザを表し、これが多次元の購買記録で表されている場合、クラスタリングとは似た購買傾向のユーザをクラスターとしてまとめていくことです。 クラスターは潜在変数です。時間と共にクラスタリング構造が変化し、例えば、3個のクラスターが4個のクラスターに変化するとして、そのような変化を潜在的ダイナミクスと呼んでいます。 潜在的ダイナミクスを検知することを潜在構造変化検知と呼んでいます。これはデータの表面ではわからない、データに内在する本質的な変化を読む解くことを意味しています。
我々は潜在構造変化検知を実現する方法として
といった概念を開発しました。そこでは、潜在構造変化を検知するのみでなく、その予兆を検知し、信頼できる早期警戒信号を出すための理論を構築しています。
潜在的ダイナミクスの成果はKDD2019におけるMDL tutorial資料に見ることができます。
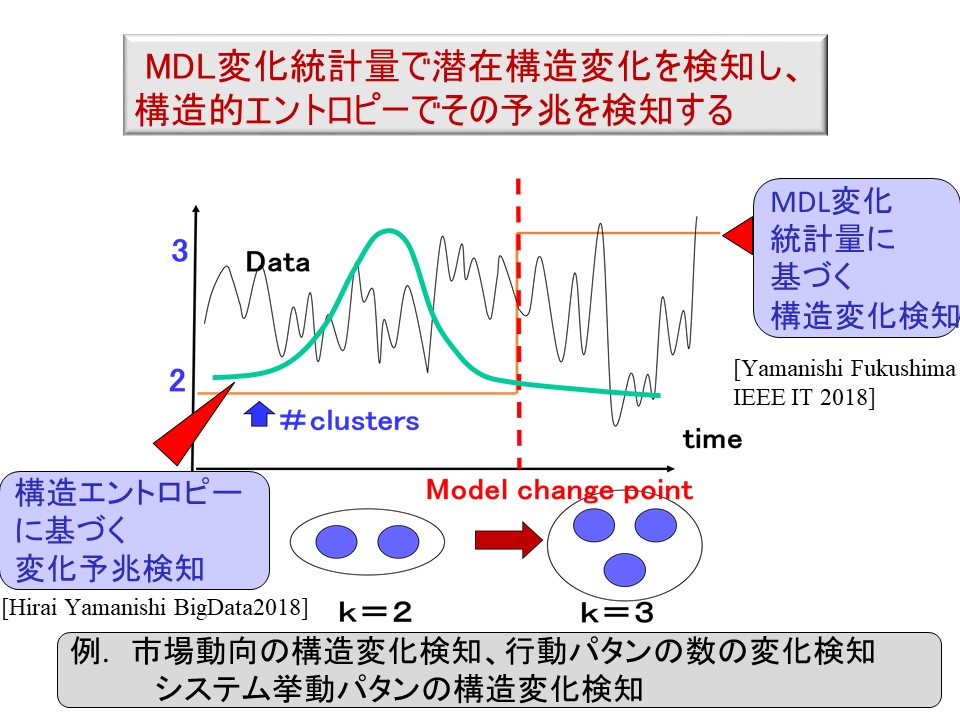
図7: MDL変化統計量に基づく潜在構造変化検知
5. 計算論的眼科学(2012年―現在)
東大付属病院眼科教室と共同で機械学習技術を眼科学に応用しています。特に、緑内障進行予測や緑内障診断という分野に取り組んでいます。
緑内障の進行具合を測るのに、Hymphry Fied Analyzerという機器で計測された視野感度データを用います。視野感度の時系列から将来の視野感度を予測するのが緑内障進行予測です。
ところが、線形回帰を直接適用しても良い予測ができません。なぜなら、一人当たりの患者のデータが少ないからです。そこで、似たような緑内障パターンをもつ患者のデータを有効活用して緑内障進行予測を行う技術を開発しました。それは、クラスタリングに基づく方法、行列分解に基づく方法などです。これにより患者個人のデータからの線形回帰よりも有意に高い予測精度を実現しました。

図8: 分解型正規化最尤符号長規準(DNML)
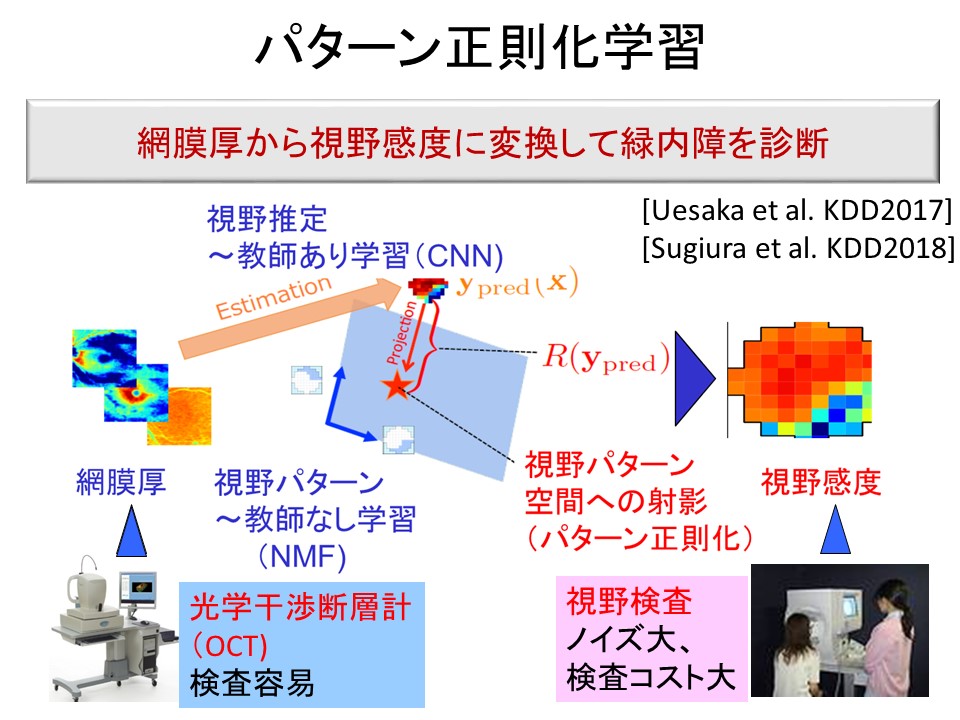
図9: パターン正則化学習
6. 予兆情報学の研究(2019年―現在)
多次元時系列データから異常や変化の出現を検知することはビッグデータ解析において重要なテーマです。なぜなら異常や変化は、データの背後に在る大きなイベントと結びつくことが多いからです。例えば、複数のセンサーデータから異常検知することは、システムの重大な障害やセキュリティ上の被害の検知を可能にします。このような異常や変化は突然起こるとは限りません。むしろ、漸進的に出現し、過渡期に予兆が現れる場合があります。そこで、変化の「予兆」を早期に検知し、その理由を説明するためのAI・機械学習の方法論を新たに生み出すことを目的として予兆情報学の研究を立ち上げました。
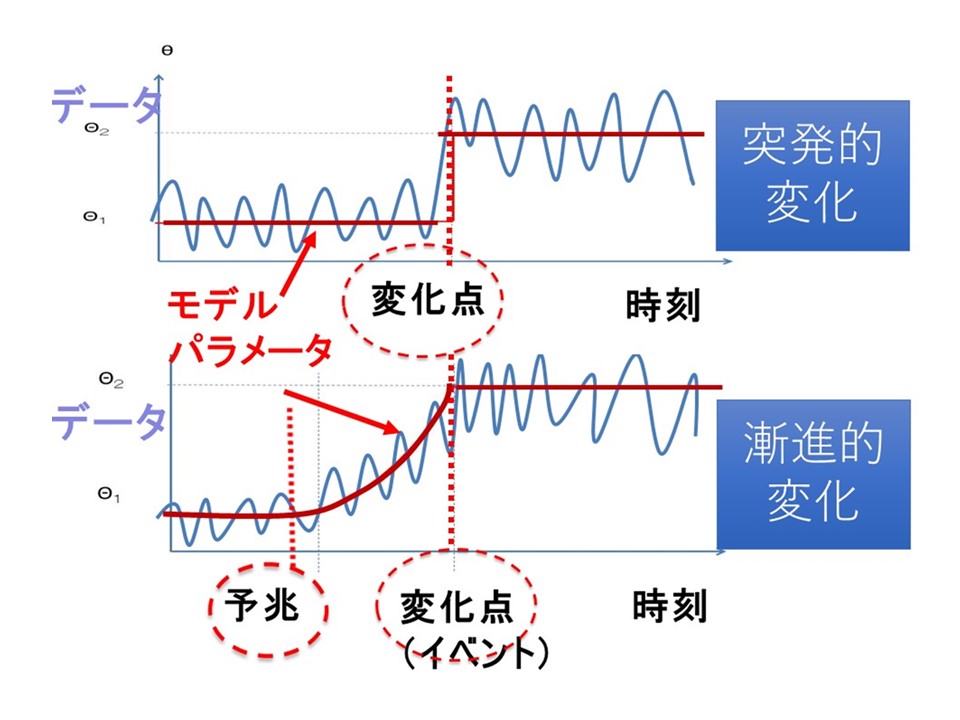
図10: 漸進的変化と予兆検知
予兆検知には2つの側面があります。1つは危機的なイベントを早期に検知し、甚大な被害やリスクを事前に回避するというものです。これをforward-lookingな予兆検知と呼びます。一方、後ろ向きに変化の予兆を発見し、その原因を究明することにより、今後の危機管理について根本的な対策を立てます。これをbackward-lookingな予兆検知と呼びます。
予兆情報学では、そのような「異常・変化の予兆検知」の数理的理論を構築し、学術的に強固な基盤を確立することを目指しています。 また、本理論を経済学・医学のデータに適用実証し、現実に通用する強い理論体系を構築します。
具体的には、経済学では、金融取引や不動産価格・取引のデータを対象にして、経済危機の予兆を早期発見し、その原因解明を行うことを目的とします。医学では、患者のプロファイルと各種検査データの時系列から、緑内障進行や脳血管系疾患の発症の予兆を早期検知することを目的とします。いずれも経済学や医学の領域知識と、AI/機械学習の方法論を融合し、新たな分野融合の学問領域としての「予兆情報学」の創成を目指します。